
Introduction
Have you ever asked ChatGPT or any other Large Language Models (LLMs) about your company’s internal process or client data and got a confident but completely wrong answer?
That’s because most Large Language Models (LLMs) are trained on public internet data, not your private business information. They can’t access internal documents, reports, or systems — making them less useful for company-specific tasks.
This is where Retrieval-Augmented Generation (RAG) comes in. RAG allows AI to securely use your own data, combining its language understanding with your organization’s unique knowledge to deliver accurate, context-aware answers.
What is a Large Language Model (LLM)?
Large Language Models (LLMs) like GPT, Claude, or LLaMA are advanced AI systems trained on huge amounts of public text data. Their goal is to understand and generate human-like responses — enabling tasks such as Q&A, summarization, image captioning, and code generation.
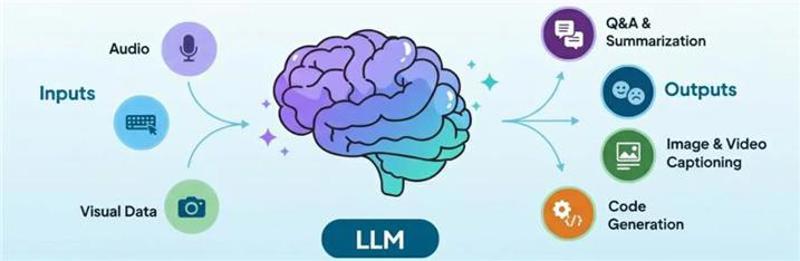
The Limitations of Traditional LLMs
Not connected to your data: They can’t access your internal files, databases, or documents.
Outdated knowledge: Their training data stops at a certain point — missing recent updates.
Hallucinations: They sometimes generate confident but incorrect answers.
Slow updates: Retraining them with new data takes a lot of time and resources.
How LLMs Are Typically Trained
Static / Predefined Data:
LLMs are trained once on large, frozen datasets — like books, websites, and code — meaning they can’t adapt to new or private information later.
Dynamic / Live Knowledge (via RAG):
With Retrieval-Augmented Generation (RAG), models can access the latest or domain-specific data in real time, without retraining — giving you accurate, context-aware answers from your own sources.
What is RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) is an advanced AI technique that enhances how language models work. Instead of relying only on their pre-trained knowledge, RAG allows models to access and use external data sources in real time.
It combines two key steps:
Retrieval: The system searches and pulls the most relevant information from your data — such as documents, databases, or wikis.
Generation: The AI then uses that retrieved information to generate a precise, context-aware, and reliable answer.
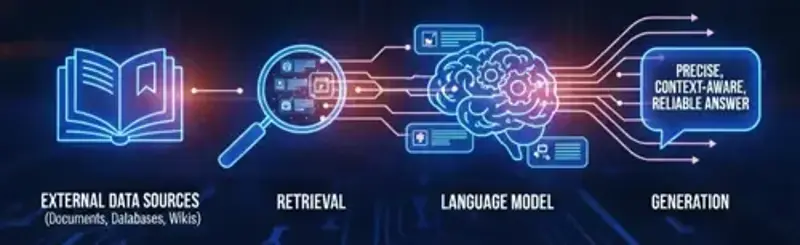
The main goal of RAG is to make AI models smarter and more useful by enabling them to understand and respond using your organization’s private or domain-specific knowledge, not just what’s available on the internet.
How RAG Works – The Architecture
Retrieval-Augmented Generation (RAG) bridges the gap between your company’s private data and the intelligence of Large Language Models (LLMs). Instead of relying only on public knowledge, RAG allows AI to access and use your internal information to generate accurate, context-aware responses.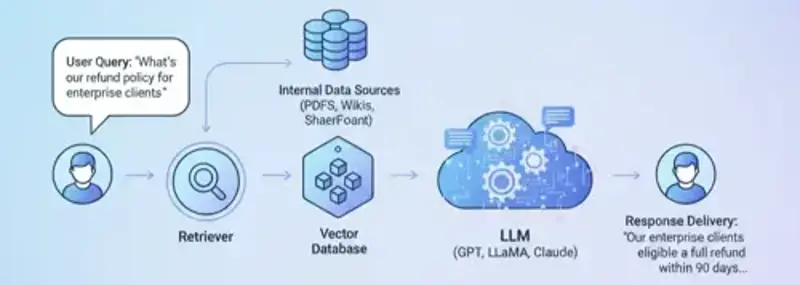
Here’s how it works step by step:
User Query: The process starts when a user asks a question — for example, “What’s our refund policy for enterprise clients?”
Retriever: The system searches internal data sources such as PDFs, wikis, SharePoint, or databases for relevant information.
Vector Database: Retrieved content is broken into small, meaningful chunks and stored for quick and precise retrieval.
LLM Generation: The LLM uses this context to generate a clear, factual, and business-aware response.
Response Delivery: The user receives a natural, accurate, and data-grounded answer tailored to the organization’s knowledge.
With RAG vs. Without RAG
RAG significantly improves how AI interacts with your organization’s data compared to traditional LLMs. Here’s a quick comparison:
Feature | Without RAG | With RAG |
|---|---|---|
Data Access | Limited to public knowledge | Can access and use your private company data |
Accuracy | May hallucinate or provide incorrect answers | Responses are grounded in real, internal data |
Updates | Requires costly and time-consuming retraining | Instantly updated by refreshing the data index |
Cost | High due to frequent retraining | Lower, as only the data index needs updating |
Usefulness | Provides general answers | Delivers domain-specific, business-relevant insights |
Benefits of Using RAG
Use your private data securely: AI can access your internal knowledge without exposing it publicly.
Real-time updates without retraining: Keep answers current by updating your data index, no full model retraining required.
Reduces hallucinations and improves accuracy: Responses are grounded in real, verified data.
Customizable sources: You control which documents, databases, or APIs the AI can access.
Cost-effective and efficient: Only relevant information is retrieved, reducing computational load.
Common Implementation Challenges
While RAG is powerful, setting it up requires careful planning:
Selecting the right vector database and embedding model for your data.
Ensuring data security and proper access control for sensitive information.
Efficiently managing large-scale document ingestion and updates.
Balancing retrieval speed vs. accuracy to optimize user experience.
Designing effective prompt templates to inject context for the LLM without overwhelming it.
Conclusion
Retrieval-Augmented Generation (RAG) transforms general-purpose AI into a domain expert that truly understands your business, your customers, and your proprietary data. By combining the reasoning power of Large Language Models (LLMs) with your organization’s own knowledge, RAG ensures responses are accurate, secure, and contextually relevant. This makes AI enterprise-ready, turning static information into dynamic, up-to-date insights that empower smarter decision-making and more reliable interactions.